What is the best way to build your code? How can you ensure repeatable deploys? What does build and deployment look like in a devops, continuous delivery kind of world?
I have seen many build and deployment systems that seem to make life hard for their developers and fail to deliver the value that they could.
The reason for this is that I don’t think the basic principles that help you get them right are well understood or explained. It’s equivalent to giving people screws and hammers and complaining that they hammer the screws into the wall.
I believe there are some fundamental principles around how a good build and deployment pipeline should work, that if done right will make the majority of things you want to do with your build and deploy pipeline really easy. In particular it will give you consistent results, work fast and scale as your team grows.
If you try to use many build pipeline tools without getting this stuff right, you’ll feel like you are constantly fighting your build tools and nothing will be as easy as it should be.
I’ve only learned these principles because over time I’ve done this wrong enough times to have struggled my way to doing it well. I hope I can save you from some of the mistakes I’ve made
I think there are 7 major principles that need to be followed:
- Separation of concerns
- Quick painless builds
- Independent deployable artifacts
- Immutable deployable artifacts
- Test your deployment mechanism
- Idempotent and scalable tests
- Know what you’re testing and what you’ve tested
The basic pipeline should work something like this:
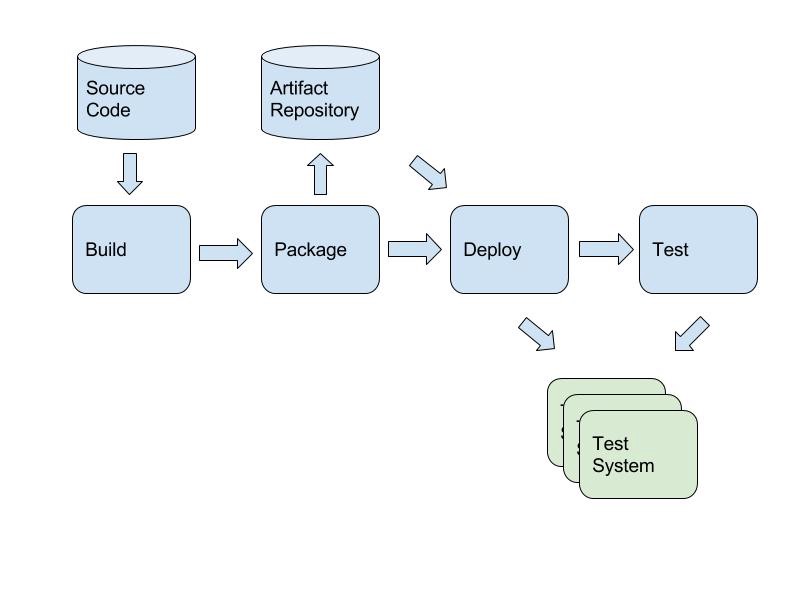
Principle 1: Separation of concerns
Many build tools are capable of operating in many of these pipelines, and so we tend to get the separation all confused. When you view your system as having just one or two pipelines, you forget to maintain the strong separation, and you end up blurring the responsibilities together.
It’s easy and simple, for example, to take something like Jenkins, which is capable of scripting builds, packaging steps, deployment steps, running tests and everything and making it do everything. That might not be bad, Jenkins is a perfectly usable tool for doing that, but the user interface means that people working with it might forget that these are separate domains.
In particular, I’ve found that separating the deployment system from the build system keeps the problem domain that they are trying to solve very constrained. If the only communication between the two systems is identification of build candidates for a deployment, then things will get much easier.
Principle 2: Quick painless builds
Every language is different, your build process for PHP might be drastically different to my build process for C++ and someone else’s build process for Go. However, almost every language is able to boil a build down to three simple concepts, build, test and package.
When I talk about build and package here,these phases get confused by the languages. The build phase takes the raw source code and converts it into an intermediate form. The package phase takes the intermediate code and ensures that everything necessary to make it complete is done.
In a language similar to Java, the build phase is the compile phase. The package is when you construct a jar, war or other container with all the dependencies in.
In some systems there may not be an actual build phase (such as in many interpreted languages like Ruby and Python). In some languages there may not be a package phase (Go, C/C++ in some cases).
These two phases almost always happen sequentially and together, so it is useful to think of them as a single phase, even if your tools might be different.
For almost every system, the build and package phase will consist of:
- Get the source code
- Compile the source code into executable objects
- Run any unit tests on the objects that require no external dependencies or runtime
- Package the objects together with any runtime dependencies
- (Optionally) perform a simple integration or smoke test of the packaged object
The output of a build and package phase should be two things; a packaged executable object with all dependencies; and a completed set of unit tests.
When we talk about unit tests, here we are talking specifically about single, fast executable tests that can assure yourself that the build is viable. This might include things like syntax checks, code linters, unit tests and possibly some functional testing. It should not include any significant user testing of journeys or integration tests of the running system.
Principle 3: Independant deployable artifacts
The end result of a build should be a “deployable artifact”. This should be as close as possible, everything needed to deploy a new version of the software, without requiring any external interactions.
I would say that this should include as much underlying software as you can cope to package into your artifact.
This can be an arguable point. In many traditional systems, libraries were split out of the deployable artifact and stored on the system as a “Shared Library”, whether a DLL, an SO, a jar file or whatever. However In today’s day and age, where storage is increasingly cheap, this is a premature optimisation.
After many experiences with configuration drift, I now err on the side that I want as much as possible to run my code, including as many libraries as possible in my deployable artifact.
If my system is supposed to run inside a major framework or platform, say a J2EE server or an apache mod-python container, then one obviously cannot easily include the platform with each build.
However, it is my experience that most of the time, artifacts should be standalone and self executing in most cases. So I might package a python interpreter, create a self executing jar with Netty or similar.
The reason behind this is that I don’t want configuration drift to change my deployable artifact. If somebody upgrades the python interpreter on the host machine, I’d like my application to not have to change. Of course there is a limit between including everything, and including as much as possible, and this varies from machine to machine.
Principle 4: Immutable artifacts
There is a key principle, that once a package has been built it should never need to be modified. Why is that?
Many systems repeat the get code, build code, fetch dependency steps of a build at repeated stages of the build and deployment pipeline. I’ve worked on some systems where at deployment time to production, the code is fetched from the source control tree and dependencies are resolved (by Bundler in this case).
The problem with this is that your deployments are no longer idempotent and repeatable. If you are fetching dependencies from the internet, they can change between deployments. If you are extremely unlucky, and you are deploying to multiple machines, they could even change within a single deployment so that your machines are inconsistent.
This behaviour makes rolling back to a previous version of your code extremely fragile, and means that deployments can change between being tested and actually going to production.
An immutable package with as many dependencies as possible gives you the most confidence that the package that was tested is what will be deployed to production.
Principle 5: Test your deployment mechanism
I’m not going to talk too much about deployment here, because I want to cover that in a separate post (there’s a lot of to cover), but the key thing is that the deployment mechanism should be able to take any built package and ensure it is running in an environment. You could use a variety of tools and techniques to make that happen from packaging up in operating system packages (MSI, RPM, Deb) to copying and unextracting a tar file and everything between.
The key principle here is that deployment must and should happen from the deployable artifact. You should never just simply be exporting source code to the server, via source control checkouts, since the risk of the code tree moving during a deployment or subsequently is too high.
You may be wondering why I’ve put deployment before testing, surely you never want to deploy something you haven’t tested? I’ve seen this, and made this mistake numerous times. The most effective tests are able to be done in a production like environment, and to get the most confidence that they represent reality, you should be using the same deployment mechanism and the same deployable artifact that you will use in production.
Therefore I encourage you to ensure that the package is valid to be deployed in your tests at the build stage, but then deploy it to a testing environment and run the tests in situ in the testing environment rather than mocking, faking or virtualising the test environment since if you do that configuration drift will eventually kill you!
If you are using the same scripts, configuration and tools to deploy during your tests, then you gain confidence that the package can be deployed by your deployment system. If you have special hand hacked ways of getting your testing infrastructure up and running, then you won’t know if there’s an issue between your package and your deployment scripts until production.
Principle 6: Idempotent and scalable tests
Once you have deployed the artifact to the testing environment, (and your deployment system should conduct a smoke test to ensure that the deployment was successful), you can then run your system tests and integration tests against the running code.
Your tests should obviously be idempotent if possible, that is to say that the running of a test should not affect another test. Individual test setup and teardown capabilities can make this happen, but you may also want the test infrastructure to put external resources into a known state when the testing suite runs. You can do this by dropping and recreating the database, making API calls to define external integrations or setting up mock services, whatever works for you.
If you are working at a scale where you have enough teams that multiple tests might be going on simultaneously, then your tests should follow some of the 12 factor principles, in that the environment under test should be injected via environment properties or configuration of some form.
This allows you to create multiple testing environments that are as separate as you might need and then dynamically inject which environment the test is running against easily. This can be as simple as a DNS name, or it can be as complicated as new database connections, third party integrations and so forth.
In a microservice world, you may want your tests to connect to production or other test versions of the other microservices. For read only tests, you may want to test against the production microservices, because this gives you the greatest confidence that the service under test is going to work in production. On the other hand if you need to write to other microservices or perform destructive testing of some form, you may want to spin up an entire fleet of microservices just for the test.
In some systems you might want to be able to apply multiple testing regimes against a deployable artifact, for example you might want to test a service in isolation before testing it against the fleet of services, or you might want to put services through security or performance testing. Any tests that might take longer or be more resource intensive you need to be able to make a decision about how often to do it and when to trigger it.
The build pipeline, a system that passes the artifact through a linear pipeline of tests, one after another, is very attractive as it means that early failures in faster tests don’t tie up resources for the slower longer tests later on. However they do reduce the feedback cycle for developers who made a change, and if you have the resources, running tests in parallel can improve the feedback loop.
Principle 7: Know what you are testing and what you’ve tested
You have potentially run a variety of tests against your deployed system. It is key that you mark the deployable artifacts in some way to indicate what tests have been done.
When your deployment system gives you options to deploy to production, by default, it should only allow artifacts that are marked as having passed all the tests to be deployed into production. This gives your teams confidence when they deploy to production, that the artifact has been through the entire process.
You may want to allow untested artifacts to bypass some of this process in emergency situations, for example if you are deploying some form of emergency patch, you may not want to run all of the performance tests or some of the slowest forms of tests.
Problems, issues and concerns
There are two issues that tend to crop up around this approach.
Database migrations
In systems where you have active databases backing the service, you might find database changes difficult to deal with. I encourage the use of separated database deployment scripts, which are a totally different deployable artifact, and dividing up the database changes from the product changes.
This means that a given deployment of a service will be dependant on the database being consistent with the expectations. As I’ve outlined before in Database migrations done right, you should aim to build systems that are backwardly compatible with the N-1 version of the database. If you also make database change scripts that compatible with the N-1 version of the software, you can bunny hop forwards and backwards.
But this can cause issues if you are running tests on systems that have inconsistent databases. In those cases, I’ve found that tracking dependency metadata, so an app relies on a given database changeset number, and the deployment system ensuring the database is at least at that change set a good way to go. In these cases, my test system might be spun up using a recent snapshot from production, and then the database changes will be applied to bring it up to the right version.
In practice, once the team has settled down with their database and the database migration process, I’ve found that this rarely causes a real issue, and the use of communication, either via physical standups, or team communication channels like Slack, can resolve this issue faster than almost any tech solution can.
Testing dependencies
The other thing I’ve found consistently still difficult with this approach is externalising the dependencies for testing.
For some systems, you may want to store your tests in a different project or deployable. But this might make keeping the tests in sync with the code tricky. In other cases you might want to package all of the test code into the deployable artifact, so that it is stored and versioned with the deployable, but that means you will be shipping the test code to the production, which is often not a good idea.
I don’t have a good solution for this. I suspect the answer is language, service and team context dependant. I’d generally start with the position that you should version the two things separately, and push the tests to the test execution system separately to the package and build of the artifact. Mostly because it is easier for teams to reason about the system this way.
How would I set it up?
Technology aside, I’d be looking for something like the following.
A build server which monitors the source repository, and on successful build can trigger a webhook or subsequent build.
A second build, triggered from the first, which makes a call to the deployment system to deploy the artifact to the test system, and then checks out the tests and executes them, if successful marking the artifact as ready.
A third and later builds, triggered on the success of the 2nd, which runs performance, security or other long or expensive tests against the infrastructure
A deployment system that supports webhooks to be driven from the build tool, has a web user interface to allow developers to issue deploys, and can also be interfaced from the team communication tool (so called ChatOps), to deploy to any manual testing environments and production.
Originally published at www.brunton-spall.co.uk on August 23, 2016.